1. What
1.1 Quick Intro
One sentence to introduce CRNN:
An end-to-end image-based sequence recognition model, composed of CNN and RNN layers, handles sequences in arbitrary length, needs no character segmentation and is efficient to deploy in real world.
1.2 Network Architecture
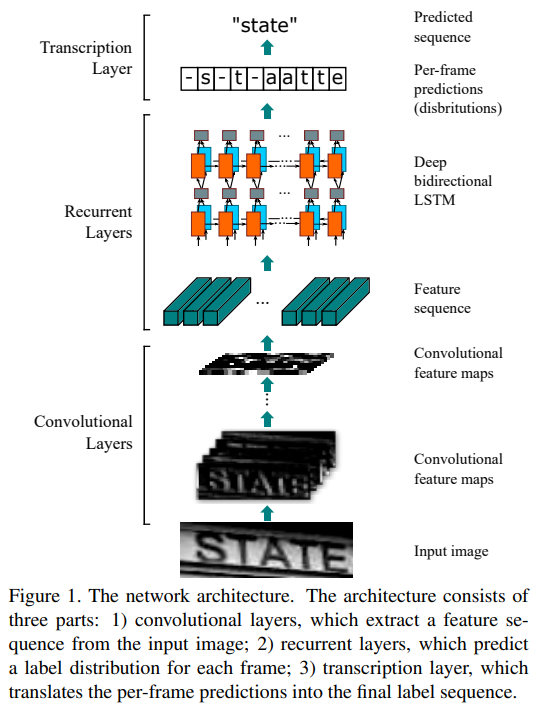
-
Use component of convolutional layers to extract feature maps.
- A sequence of feature vectors is extracted from the feature maps produced by the component of convolutional layers. Specifically, each feature vector of a feature sequence is generated from left to right on the feature maps by column. This means the i-th feature vector is the concatenation of the i-th columns of all the maps. The width of each column in our settings is fixed to single pixel.
- Send the sequence of feature vectors from output of convolutional layers to recurrent neural networks, specifically component of bidirectional LSTM layers.
- In the end, a transcription layer is used to transfer per-frame predictions to label sequence.
1.3 Details
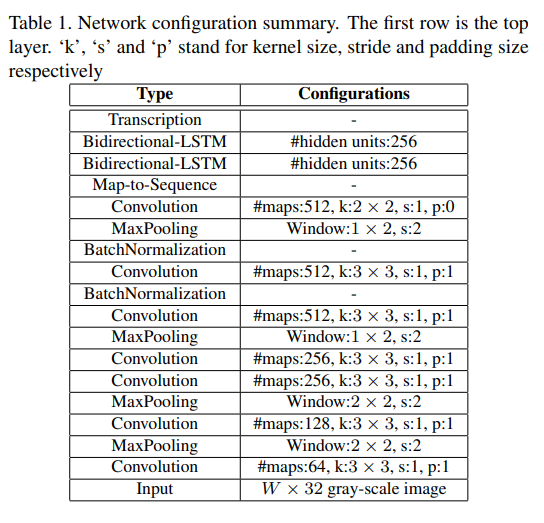
1. What is the specific component of the CNN part?
It’s VGG-like.
- VGG: first two blocks contains one 3x3 convolutional layer followed by a 2x2 Maxpooling layer, last three blocks contains two 3x3 convolutional layers followed by a 2x2 Maxpooling layer.
- However, in this model, the first four blocks are like those in VGG, but it’s followed by one convolutional layer instead of a block.
- Moreover, the stride size of Maxpooling in the third and fourth blocks is changed from 2x2 to 1x2, and Batchnormalization layers are added in the fourth block.
2. Why replace the Maxpooling stride size 2x2 with 1x2?
To be clear, 1x2 means the width stride is 1 and height stride is 2. It is consistent to the pooling layer parameter order of the paper’s code, but considering that most readers use pytorch(the parameter order is different), this might lead misunderstanding.
The reason for this design is to recognize characters that have narrow shapes, like ‘i’, ‘l’. Because it makes the width of the feature map lager.
The detail of the Maxpoling parameter setting can be found in section 2.
3. What is the function of Batchnormalization layer?
\(\begin{aligned} \mathrm{BN}(\mathbf{x}) = \boldsymbol{\gamma} \odot \frac{\mathbf{x} - \hat{\boldsymbol{\mu}}_\mathcal{B}}{\hat{\boldsymbol{\sigma}}_\mathcal{B}} + \boldsymbol{\beta}.\end{aligned}\)
where
\[\begin{aligned} \hat{\boldsymbol{\mu}}_\mathcal{B} &= \frac{1}{|\mathcal{B}|} \sum_{\mathbf{x} \in \mathcal{B}} \mathbf{x},\\ \hat{\boldsymbol{\sigma}}_\mathcal{B}^2 &= \frac{1}{|\mathcal{B}|} \sum_{\mathbf{x} \in \mathcal{B}} (\mathbf{x} - \hat{\boldsymbol{\mu}}_{\mathcal{B}})^2 + \epsilon.\end{aligned}\]Normalization makes the middle output of layers more stale. Stable middle outputs means we can set a larger learning rate, which lowers the training time.
Due to it introduces noise into the model, it also has the function of regularization.
4. What is the specific component of RNN part?
It contains two bidirectional LSTM.
LSTM is directional, it only uses past contexts. However, in image-based sequences, contexts from both directions are useful and complementary to each other. Therefore, bidirectional LSTM is used.
5. In the transcription process, CTC layer is used. What is CTC?
As described by Wikipedia, CTC(Connectionist Temporal Classification) is a type of neural network output and associated scoring function, for training recurrent neural networks (RNNs) such as LSTM networks to tackle sequence problems where the timing is variable. It can be used for tasks like on-line handwriting recognition or recognizing phones in speech audio.
Specifically, CTC helps decode the output correctly and calculate training loss.
Encode and decode
The output of RNN is per-frame, which means there might be multiple neighboring outputs are mapped to the same character. For example:
- Some character is wider than others(‘w’ and ‘m’ is wider than ‘l’ and ‘i’).
- The width of handwritten character is not sure.
Therefore, CTC removes repeating characters in output sequences. So ‘-hi-‘ and ‘-hhi-‘ are both recognized as ‘hi’.
But how about words with repeating characters like ‘better’? CTC requires to add blank character ‘-‘ between them. So ‘-b-ee-ttt-t-e-r-‘ and ‘-bb-e-t-t-e-r-‘ both represent ‘better’, but ‘-b-e-tt-e-r-‘ don’t.
Loss function
Denote the training dataset by \(X = \{ I_i, l_i \}\), where $I_i$ is the training image and $l_i$ is the ground truth label sequence; $y_i$ is per-frame predictions. The objective is to minimize the negative log-likelihood of conditional probability of ground truth:
\[\begin{aligned} Loss = -\sum_{I_i, l_i \in X} log p(l_i | y_i) \end{aligned}\]This conditional probability is defined by CTC.
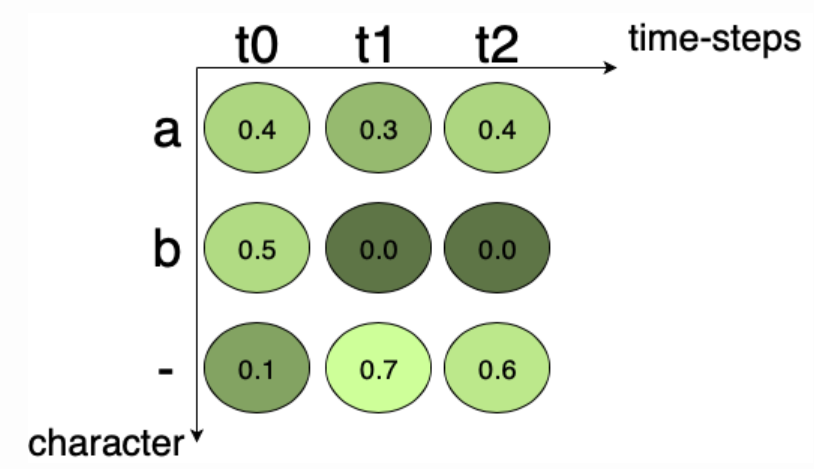
As we can see from the figure below, for example, if the ground truth is “a”, all the possible paths for “a” in Fig.3 are “aaa”, “a–”, “a-“, “aa-“, “-aa”, “–a”. Summing up the score of the individual path we get, 0.048 + 0.168 + 0.018 + 0.072 + 0.012 + 0.028 = 0.346. Then we can calculate the loss.
6. What benchmarks are used for performance evaluation?
Four popular benchmarks for scene text recognition are used for performance evaluation, namely ICDAR 2003(IC03), ICDAR 2013 (IC13), IIIT 5k-word (IIIT5k), and Street View Text (SVT).
2. How
The authors of the paper provide code implemented with Torch 7, the code mentioned here is pytorch version(thanks to this github repo)
The RNN component:
class BidirectionalLSTM(nn.Module):
def __init__(self, nIn, nHidden, nOut):
super(BidirectionalLSTM, self).__init__()
self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
self.embedding = nn.Linear(nHidden * 2, nOut)
def forward(self, input):
recurrent, _ = self.rnn(input)
T, b, h = recurrent.size()
t_rec = recurrent.view(T * b, h)
output = self.embedding(t_rec) # [T * b, nOut]
output = output.view(T, b, -1)
return output
The whole CRNN model:
class CRNN(nn.Module):
def __init__(self, imgH, nc, nclass, nh, n_rnn=2, leakyRelu=False):
#nc:input channel, nh: hidden layer in rnn
super(CRNN, self).__init__()
assert imgH % 16 == 0, 'imgH has to be a multiple of 16'
#ks: mapping kernel sizes of conv layers
ks = [3, 3, 3, 3, 3, 3, 2]
#ps: mapping padding sizes of conv layers
ps = [1, 1, 1, 1, 1, 1, 0]
#ss: mapping stride sizes of conv layers
ss = [1, 1, 1, 1, 1, 1, 1]
#nm: mapping channels of conv layers
nm = [64, 128, 256, 256, 512, 512, 512]
cnn = nn.Sequential()
def convRelu(i, batchNormalization=False):
nIn = nc if i == 0 else nm[i - 1]
nOut = nm[i]
cnn.add_module('conv{0}'.format(i),
nn.Conv2d(nIn, nOut, ks[i], ss[i], ps[i]))
if batchNormalization:
cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(nOut))
if leakyRelu:
cnn.add_module('relu{0}'.format(i),
nn.LeakyReLU(0.2, inplace=True))
else:
cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
# input size (1, 32, 128)
convRelu(0) # channel x h x w = 64 x 32 x 100
cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # 64x16x50
convRelu(1)
cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # 128x8x25
convRelu(2, True) # 256x8x25
convRelu(3) # 256x8x25
cnn.add_module('pooling{0}'.format(2),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x26
convRelu(4, True)
convRelu(5)
cnn.add_module('pooling{0}'.format(3),
nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x27
# k=2, s = 1, p = 0
convRelu(6, True) # 512x1x26
self.cnn = cnn
#after cnn, there are 512 channels, every channel has a feature map with (1, 16) dimensions
#then,we take every pixel from left to right as a sequence, which means one element in a sequence is composed of 512 pixels, one pixel from one channel.
#the input is (1, 512)now.
#every element represent one small region of the original image, and their order is the same as the order of the regions'
self.rnn = nn.Sequential(
BidirectionalLSTM(512, nh, nh),
BidirectionalLSTM(nh, nh, nclass))
def forward(self, input):
# conv features
conv = self.cnn(input)
#map2sequence
b, c, h, w = conv.size() # b, 512, 1, 26
assert h == 1, "the height of conv must be 1"
conv = conv.squeeze(2)
conv = conv.permute(2, 0, 1) # [w, b, c]
# rnn features
output = self.rnn(conv)
return output
The CTC encoder-decoder:
class strLabelConverter(object):
"""Convert between str and label.
NOTE:
Insert `blank` to the alphabet for CTC.
Args:
alphabet (str): set of the possible characters.
ignore_case (bool, default=True): whether or not to ignore all of the case.
"""
def __init__(self, alphabet, ignore_case=True):
self._ignore_case = ignore_case
if self._ignore_case:
alphabet = alphabet.lower()
self.alphabet = alphabet + '-' # for `-1` index
self.dict = {}
for i, char in enumerate(alphabet):
# NOTE: 0 is reserved for 'blank' required by wrap_ctc
self.dict[char] = i + 1
def encode(self, text):
"""Support batch or single str.
Args:
text (str or list of str): texts to convert.
Returns:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: encoded texts.
torch.IntTensor [n]: length of each text.
"""
if isinstance(text, str):
text = [
self.dict[char.lower() if self._ignore_case else char]
for char in text
]
length = [len(text)]
elif isinstance(text, collections.Iterable):
length = [len(s) for s in text]
text = ''.join(text)
text, _ = self.encode(text)
return (torch.IntTensor(text), torch.IntTensor(length))
def decode(self, t, length, raw=False):
"""Decode encoded texts back into strs.
Args:
torch.IntTensor [length_0 + length_1 + ... length_{n - 1}]: encoded texts.
torch.IntTensor [n]: length of each text.
Raises:
AssertionError: when the texts and its length does not match.
Returns:
text (str or list of str): texts to convert.
"""
if length.numel() == 1:
length = length[0]
assert t.numel() == length, "text with length: {} does not match declared length: {}".format(t.numel(), length)
if raw:
return ''.join([self.alphabet[i - 1] for i in t])
else:
char_list = []
for i in range(length):
if t[i] != 0 and (not (i > 0 and t[i - 1] == t[i])):
char_list.append(self.alphabet[t[i] - 1])
return ''.join(char_list)
else:
# batch mode
assert t.numel() == length.sum(), "texts with length: {} does not match declared length: {}".format(t.numel(), length.sum())
texts = []
index = 0
for i in range(length.numel()):
l = length[i]
texts.append(
self.decode(
t[index:index + l], torch.IntTensor([l]), raw=raw))
index += l
return texts